在高校教育管理领域,毕业生就业数据的有效管理与深度分析一直是提升教学质量、优化专业设置的重要依据。传统的人工记录与Excel统计方式存在数据分散、更新滞后、统计维度单一等局限性,难以满足现代高校对就业质量实时监控与多维度分析的需求。针对这一痛点,设计并实现了一套基于SSM(Spring+SpringMVC+MyBatis)架构的毕业生就业智慧分析平台,通过统一数据管理、自动化统计分析和可视化呈现,为高校管理者提供数据驱动的决策支持。
系统采用经典的三层架构设计,展现层使用SpringMVC框架处理Web请求和视图解析,业务逻辑层由Spring框架管理服务组件和事务控制,数据访问层通过MyBatis实现与MySQL数据库的灵活交互。前端采用Bootstrap框架构建响应式界面,并集成ECharts可视化库实现动态图表渲染。项目使用Maven进行依赖管理,确保第三方库版本的一致性。
数据库设计包含10张核心表,其中就业去向表(employment_destination)采用多维度设计思路:
CREATE TABLE employment_destination (
id INT PRIMARY KEY AUTO_INCREMENT,
student_id INT NOT NULL,
company_name VARCHAR(100) NOT NULL,
job_position VARCHAR(50) NOT NULL,
industry_category VARCHAR(30),
employment_type ENUM('全职','兼职','实习'),
salary_range VARCHAR(20),
employment_date DATE,
city VARCHAR(20),
is_related_major BOOLEAN DEFAULT TRUE,
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (student_id) REFERENCES student(id)
);
该表通过industry_category字段实现行业分类统计,salary_range字段支持薪资区间分析,is_related_major字段用于计算专业对口率。日期字段employment_date与create_time分别记录实际就业时间和数据入库时间,满足不同时间维度的对比分析需求。
专业信息表(major)采用树形结构设计,支持院系-专业的多级关联:
CREATE TABLE major (
id INT PRIMARY KEY AUTO_INCREMENT,
major_name VARCHAR(40) NOT NULL,
department_id INT NOT NULL,
enrollment_year YEAR,
student_count INT DEFAULT 0,
employment_target_rate DECIMAL(5,2),
INDEX idx_department (department_id),
INDEX idx_year (enrollment_year)
);
通过enrollment_year字段实现按入学年份的就业趋势追踪,employment_target_rate字段预设就业率目标值,便于实际达成率的实时比对。复合索引设计显著提升多条件查询性能。
统计分析模块的核心服务类实现多维度数据聚合功能:
@Service
public class EmploymentAnalysisService {
@Autowired
private EmploymentMapper employmentMapper;
public Map<String, Object> getMajorComparison(String year) {
List<Map<String, Object>> result = employmentMapper.selectMajorEmploymentStats(year);
return result.stream().collect(Collectors.toMap(
map -> (String) map.get("majorName"),
map -> Map.of(
"employmentRate", map.get("employmentRate"),
"avgSalary", map.get("avgSalary"),
"relatedRate", map.get("relatedRate")
)
));
}
public List<SalaryDistribution> getSalaryDistribution(String majorId) {
return employmentMapper.selectSalaryDistributionByMajor(majorId)
.stream().map(row -> new SalaryDistribution(
(String) row.get("range"),
((Long) row.get("count")).intValue()
)).collect(Collectors.toList());
}
}
就业数据可视化功能通过RESTful接口提供数据服务:
@RestController
@RequestMapping("/api/analysis")
public class AnalysisController {
@GetMapping("/major-trend")
public ResponseEntity<Map<String, Object>> getMajorTrend(
@RequestParam String majorId,
@RequestParam Integer years) {
List<EmploymentTrend> trends = analysisService.getEmploymentTrend(majorId, years);
Map<String, Object> result = new HashMap<>();
result.put("categories", trends.stream().map(EmploymentTrend::getYear).collect(Collectors.toList()));
result.put("rates", trends.stream().map(EmploymentTrend::getRate).collect(Collectors.toList()));
return ResponseEntity.ok(result);
}
}
MyBatis映射文件实现复杂的多表关联查询:
<select id="selectMajorEmploymentStats" resultType="map">
SELECT m.major_name AS majorName,
COUNT(DISTINCT s.id) AS totalStudents,
ROUND(COUNT(DISTINCT ed.id) * 100.0 / COUNT(DISTINCT s.id), 2) AS employmentRate,
ROUND(AVG(CASE WHEN ed.salary_range IS NOT NULL
THEN CAST(SUBSTRING_INDEX(ed.salary_range, '-', 1) AS UNSIGNED) END)) AS avgSalary,
ROUND(SUM(ed.is_related_major) * 100.0 / COUNT(ed.id), 2) AS relatedRate
FROM major m
LEFT JOIN student s ON m.id = s.major_id
LEFT JOIN employment_destination ed ON s.id = ed.student_id
WHERE YEAR(s.enrollment_year) = #{year}
GROUP BY m.id
</select>
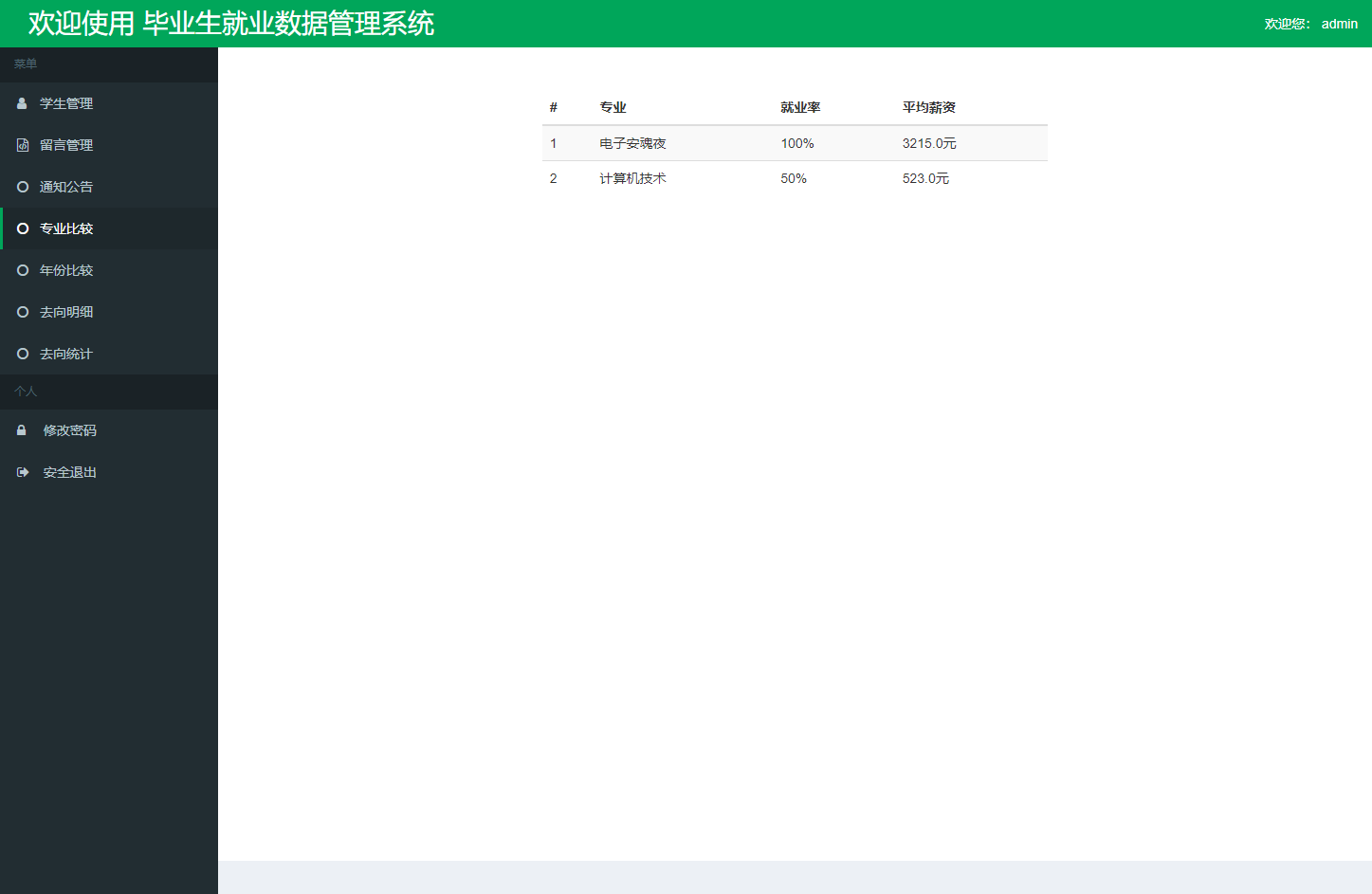
系统管理员可通过专业对比功能查看各专业核心指标:
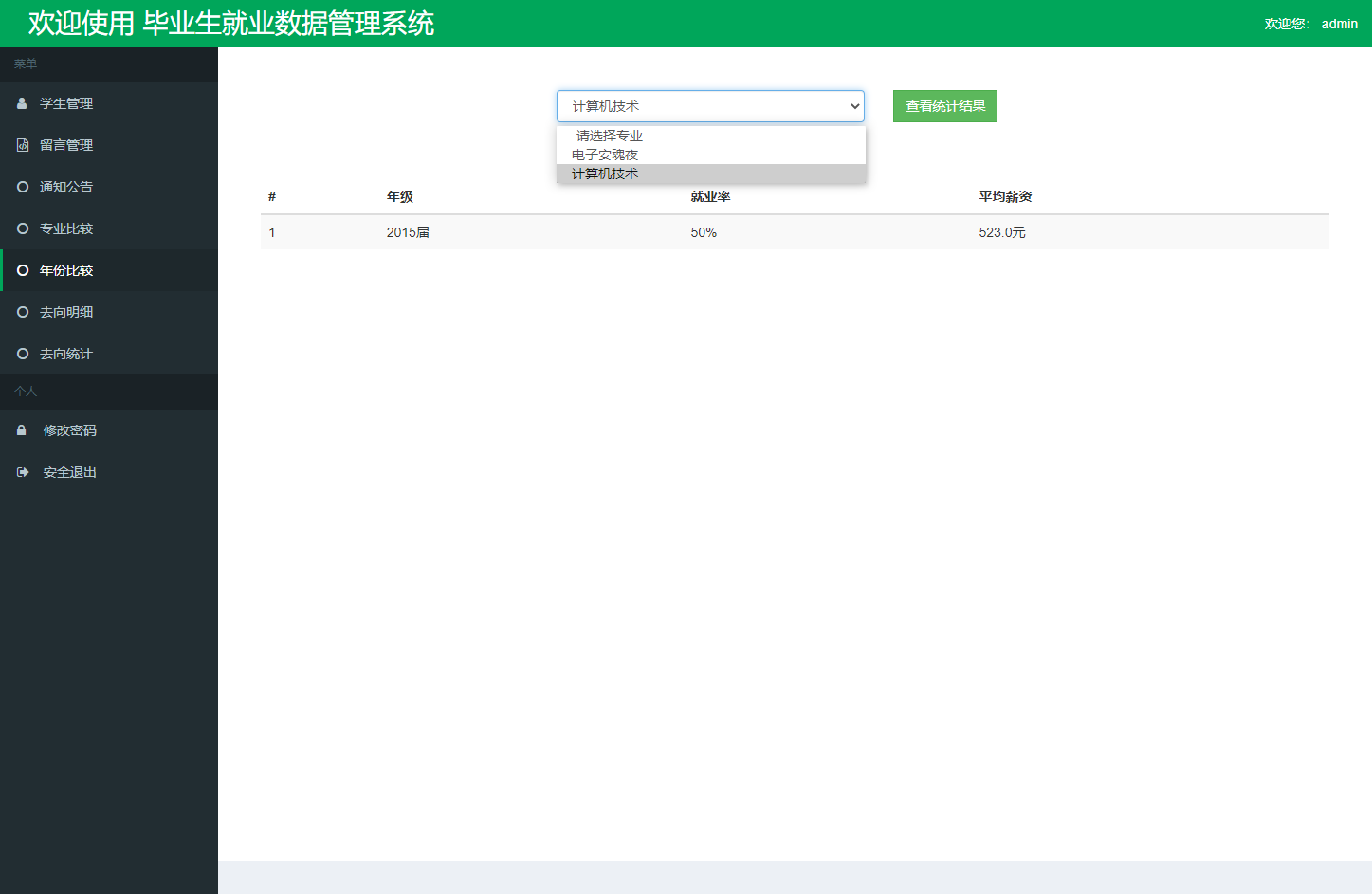
年度对比分析模块支持多年度数据趋势追踪:
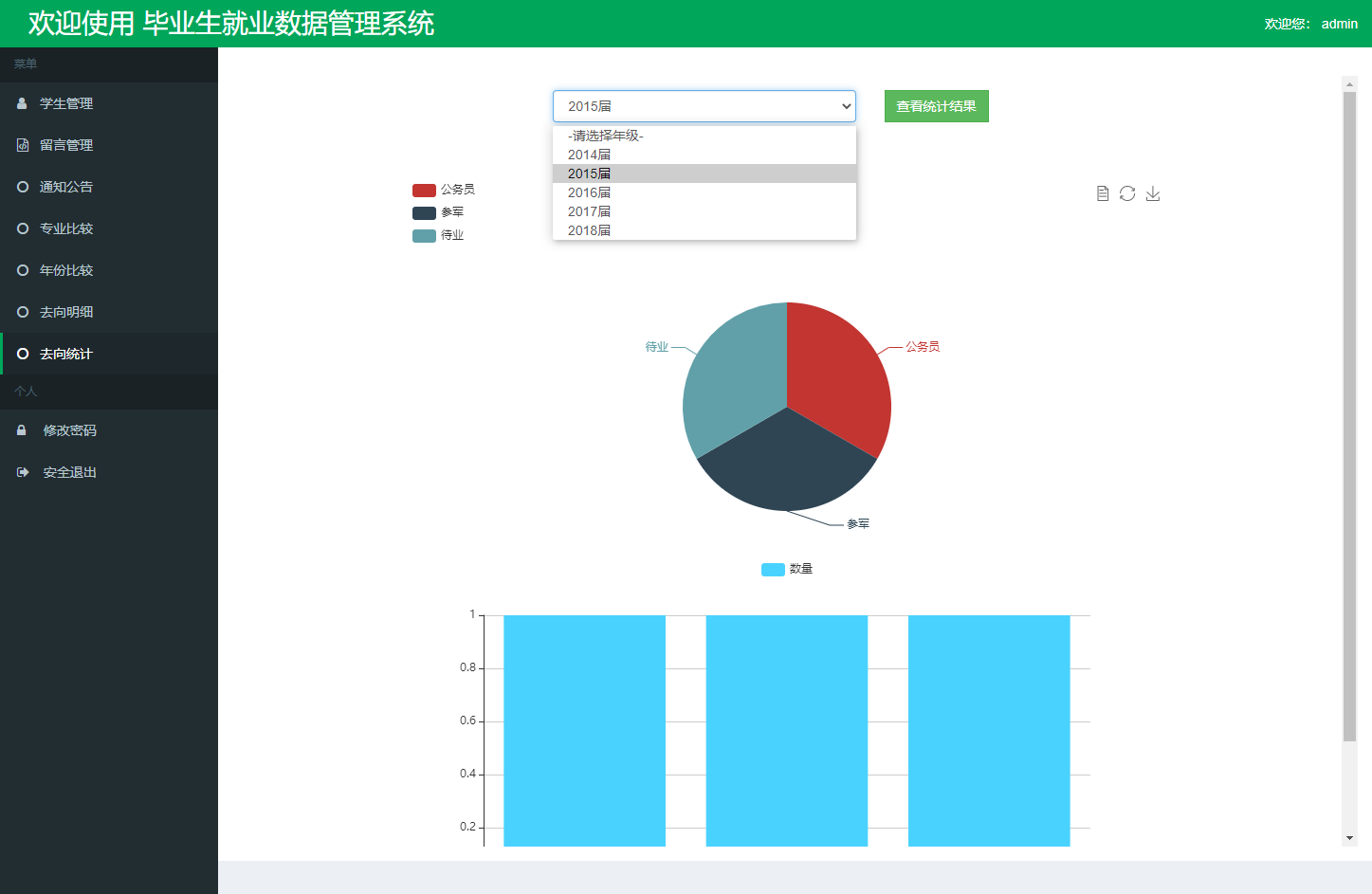
就业去向统计界面提供详细的数据钻取功能:
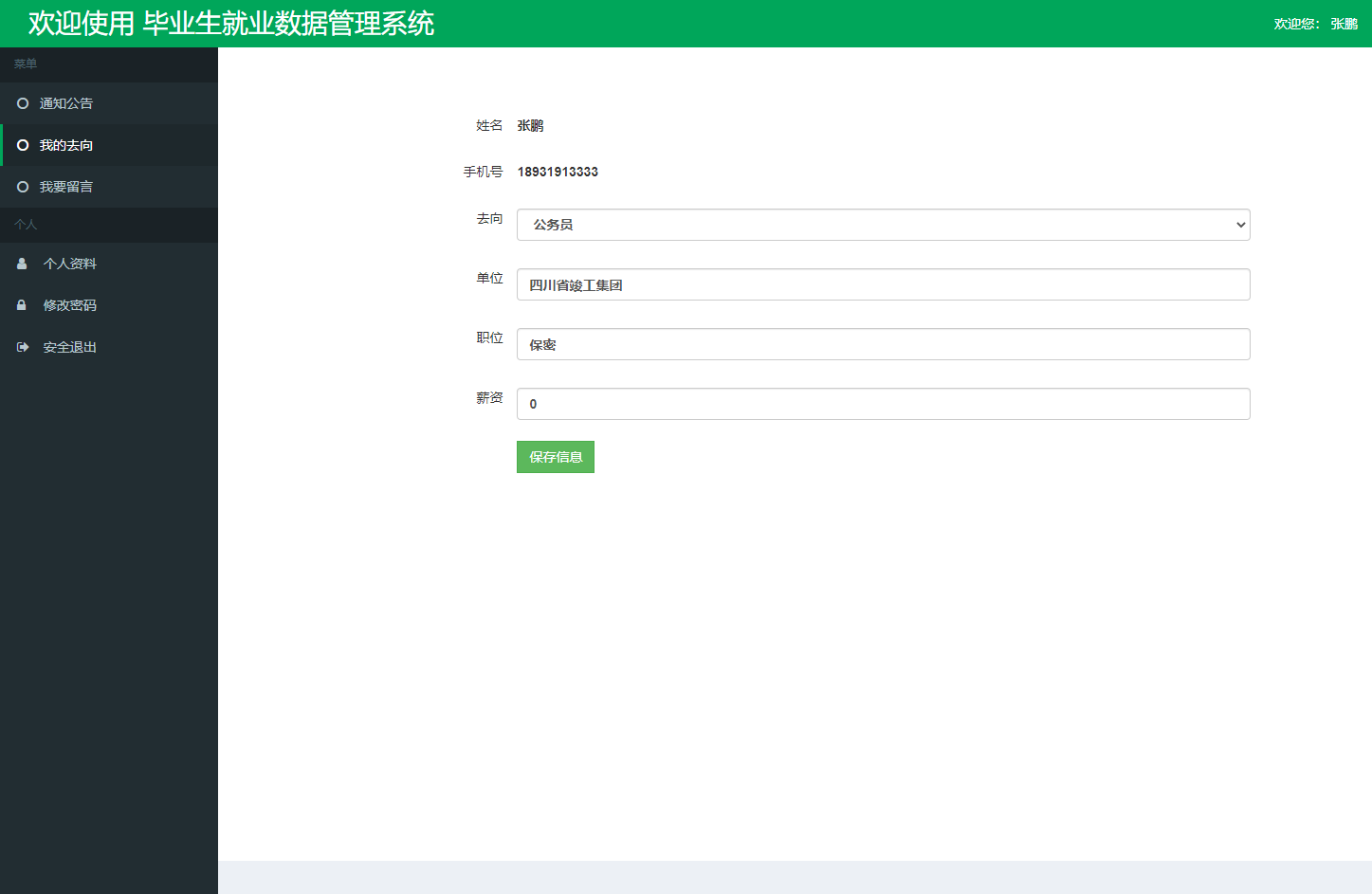
学生端个人就业信息管理界面:
消息管理模块实现系统通知的精准推送:
实体关系模型设计注重业务逻辑的完整性。Student实体与EmploymentDestination实体建立一对多关联,支持学生多次就业记录的追踪。Major实体通过department_id与院系信息关联,形成完整的组织架构。所有实体均包含create_time和update_time审计字段,满足数据追溯需求。
系统在事务管理方面采用Spring声明式事务控制,确保数据操作的一致性:
@Service
@Transactional
public class StudentServiceImpl implements StudentService {
@Override
@Transactional(rollbackFor = Exception.class)
public void importEmploymentData(List<EmploymentDTO> dataList) {
for (EmploymentDTO dto : dataList) {
Student student = studentMapper.selectByStudentNumber(dto.getStudentNumber());
if (student != null) {
EmploymentDestination destination = new EmploymentDestination();
BeanUtils.copyProperties(dto, destination);
destination.setStudentId(student.getId());
employmentMapper.insert(destination);
// 更新学生就业状态
student.setEmploymentStatus(EmploymentStatus.EMPLOYED);
studentMapper.update(student);
}
}
}
}
系统未来可从以下方向进行功能扩展:首先,集成机器学习算法实现就业预测,通过历史数据训练模型预测各专业未来就业趋势;其次,开发移动端应用,利用React Native技术构建跨平台移动应用,方便管理人员随时随地查看数据;第三,建立企业评价体系,收集毕业生对就业单位的满意度反馈,形成企业质量评估数据库;第四,实现数据自动化采集,通过与企业招聘系统API对接减少人工录入;最后,增强数据安全机制,采用数据脱敏技术和操作日志审计,确保敏感信息的安全性。
该平台通过系统化的数据管理和智能分析,有效解决了高校就业信息管理的核心痛点。模块化设计使系统具备良好的扩展性,可视化分析功能为决策提供直观支持。随着数据积累的不断增加,系统将发挥更大的数据价值,成为高校就业指导工作的核心工具。