基于SSM框架的毕业生就业信息管理与分析系统 - 源码深度解析
在高校教育管理信息化进程中,毕业生就业数据的管理与分析一直是关键且复杂的挑战。传统的手工记录和Excel表格管理方式存在数据分散、统计效率低、决策支持不足等痛点。针对这一需求,我们设计并实现了一套智能就业数据管理平台,该系统基于成熟的SSM(Spring+SpringMVC+MyBatis)技术栈构建,为高校就业工作提供了全方位的数字化解决方案。
系统架构与技术栈
该平台采用典型的三层架构模式,实现了前后端分离的设计理念:
- 前端层:使用HTML/CSS/JavaScript构建响应式用户界面,确保良好的用户体验
- 控制层:基于SpringMVC框架,采用RESTful风格设计接口,配合拦截器实现权限控制
- 业务层:Spring框架的IoC容器负责管理所有业务组件,通过依赖注入实现组件间的松耦合
- 持久层:使用MyBatis实现数据持久化,通过XML配置实现灵活的SQL映射
技术选型亮点:
- 项目采用Maven进行依赖管理,确保第三方库版本的统一性和兼容性
- 数据库选用MySQL 5.7+,字符集设置为utf8mb4,支持完整的Unicode字符,满足多语言需求
- 结合PageHelper插件实现高效的分页查询,提升大数据量下的查询性能
- 整个系统部署在Tomcat 8+服务器上,形成了稳定可靠的企业级应用架构
数据库设计亮点
核心表关系设计
系统数据库采用符合第三范式的关系设计,主要包含用户表、就业信息表、招聘会表等10个核心表。其中t_zhaopinbm(招聘会报名表)的设计体现了良好的外键关联策略:
CREATE TABLE `t_zhaopinbm` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`t_bianhao` varchar(255) DEFAULT NULL COMMENT '报名编号',
`t_tongyi` varchar(255) DEFAULT NULL COMMENT '是否审核同意',
`t_bz` longtext DEFAULT NULL COMMENT '备注',
`addTime` datetime DEFAULT NULL COMMENT '插入数据库时间',
`zhaopin_id` int(11) DEFAULT NULL COMMENT '对应Zhaopin表的ID,在这里作为外键',
`user_id` int(11) DEFAULT NULL COMMENT '对应User表的ID,在这里作为外键',
PRIMARY KEY (`id`),
KEY `FK416D48192D852AE4` (`user_id`),
KEY `FK416D481976AB75D0` (`zhaopin_id`),
CONSTRAINT `FK416D48192D852AE4` FOREIGN KEY (`user_id`) REFERENCES `t_user` (`id`),
CONSTRAINT `FK416D481976AB75D0` FOREIGN KEY (`zhaopin_id`) REFERENCES `t_zhaopin` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='招聘会报名管理表'
设计优势:
- 通过
zhaopin_id和user_id两个外键分别关联招聘会信息和用户信息,建立了完整的报名业务逻辑 - 合理的索引设置优化了联表查询性能,外键约束保证了数据的参照完整性
- InnoDB存储引擎支持事务处理,确保数据操作的原子性和一致性
数据字典表设计
系统设计了多个数据字典表,如t_xinzfw(薪资范围表)、t_hangye(行业分类表)等,这些表采用统一的字段结构:
CREATE TABLE `t_hangye` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`t_hy` varchar(255) DEFAULT NULL COMMENT '行业',
`t_bz` longtext DEFAULT NULL COMMENT '备注',
`addTime` datetime DEFAULT NULL COMMENT '插入数据库时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='公司行业表'
设计特点:
- 统一的设计模式便于维护和扩展,降低了系统复杂度
addTime字段为数据审计提供了支持,满足合规性要求longtext类型的备注字段满足了大文本存储需求,支持详细的描述信息
核心功能实现
毕业生就业信息管理
系统核心的就业信息管理功能由BiysController控制器实现,该控制器采用注解方式配置路由和依赖注入:
@Controller
@RequestMapping(value = "Biys")
public class BiysController {
@Autowired
private BiysService biysService;
@Autowired
private DanweixzService danweixzService;
@Autowired
private HangyeService hangyeService;
@Autowired
private XinzfwService xinzfwService;
@Autowired
private UserService userService;
@RequestMapping(value = "/initPage.do")
public String initPage(HttpServletRequest request, Model model) {
List<Danweixz> listDanweixz = danweixzService.getList(null, null);
model.addAttribute("listDanweixz", listDanweixz);
List<Hangye> listHangye = hangyeService.getList(null, null);
model.addAttribute("listHangye", listHangye);
List<Xinzfw> listXinzfw = xinzfwService.getList(null, null);
model.addAttribute("listXinzfw", listXinzfw);
return "Biys/add";
}
}
技术实现亮点:
- 使用Spring的
@Autowired注解实现依赖注入,降低组件耦合度 - 在页面初始化时,控制器通过多个Service层组件加载所需的数据字典信息
- 采用Model对象向前端传递数据,实现业务逻辑与视图的清晰分离
![]()
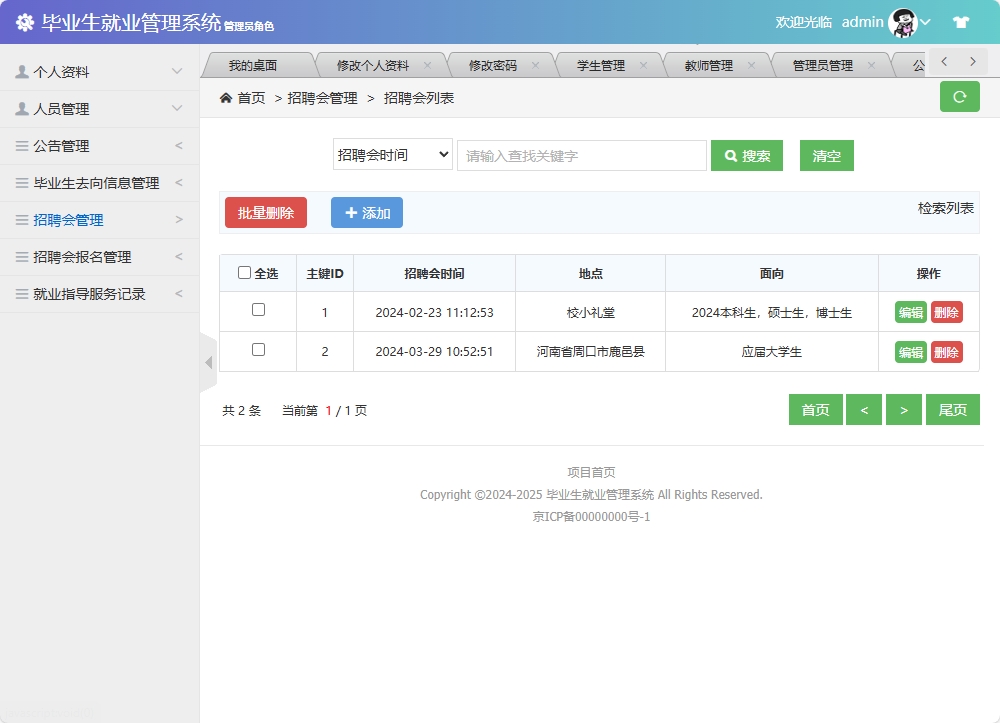
招聘会管理模块
招聘会管理实现了完整的CRUD操作,包括招聘会信息的添加、修改、删除和查询:
@RequestMapping(value = "/add.do")
@Tip(operation = "添加招聘会")
public String add(Zhaopin zhaopin, HttpServletRequest request) {
try {
zhaopin.setAddTime(new Date());
zhaopinService.save(zhaopin);
request.setAttribute("message", "添加成功");
} catch (Exception e) {
request.setAttribute("message", "添加失败");
e.printStackTrace();
}
return "message";
}
功能特色:
- 通过
@Tip自定义注解实现操作日志的记录,结合AOP技术实现统一的日志处理 - 自动设置时间戳,确保数据的时间一致性
- 完善的异常处理机制,提供友好的用户反馈
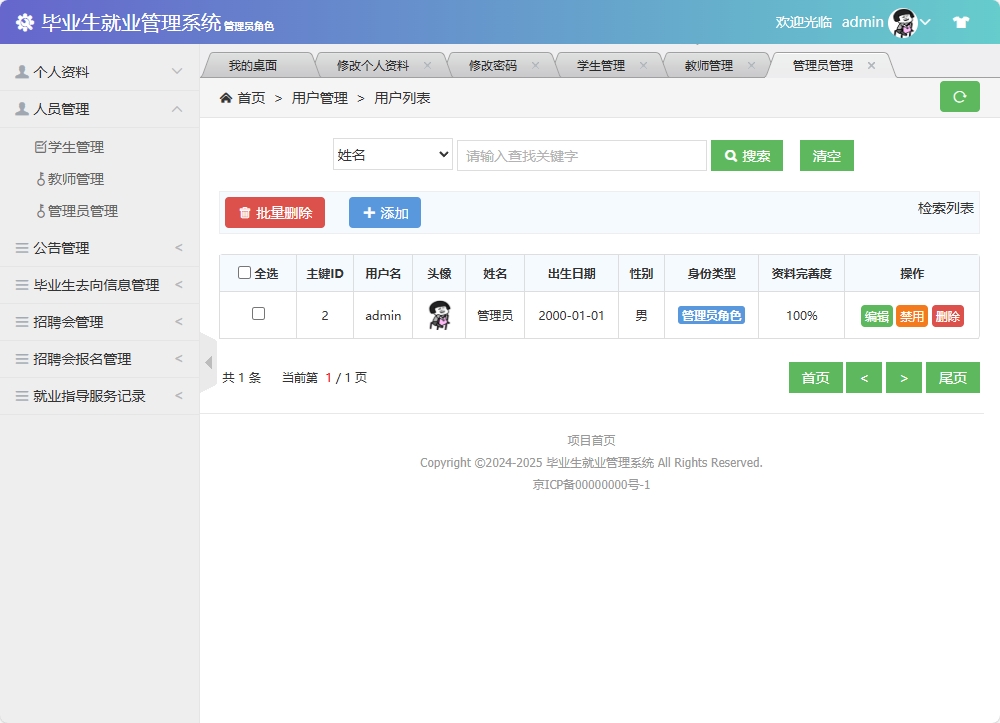
多角色权限控制
系统基于用户类型字段u_type实现精细化的权限控制。SpringMVC拦截器负责验证用户权限:
public class AuthInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request,
HttpServletResponse response, Object handler) throws Exception {
HttpSession session = request.getSession();
User user = (User) session.getAttribute("user");
if (user == null) {
response.sendRedirect(request.getContextPath() + "/login.jsp");
return false;
}
// 根据user.getU_type()进行角色权限验证
String requestURI = request.getRequestURI();
if (!hasPermission(user, requestURI)) {
response.sendError(403, "无权限访问");
return false;
}
return true;
}
}
权限管理机制:
- 基于会话的用户认证,确保系统安全性
- 细粒度的权限控制,不同角色只能访问授权范围内的功能
- 自动重定向到登录页面,提升用户体验
数据统计与分析
系统通过复杂的SQL查询实现多维度数据统计,包括各专业就业率、行业分布、薪资水平等关键指标:
<!-- MyBatis映射文件中的统计查询 -->
分析功能特点:
- 支持实时数据统计,为决策提供及时支持
- 多维度数据分析,全面反映就业状况
- 可视化数据展示,直观呈现统计结果
总结
本系统基于SSM框架构建,通过合理的架构设计和细致的功能实现,为高校毕业生就业管理提供了完整的解决方案。系统具有良好的可扩展性和维护性,为后续功能升级奠定了坚实基础。