在学术研究领域,文献资料的管理与利用效率直接关系到科研工作的进程。面对海量的PDF、Word等格式的文献文件,研究人员常常陷入资料分散、检索困难、版本混乱的困境。传统依靠本地文件夹分类的方式,不仅难以实现跨设备访问和团队协作,更无法支持基于元数据的高效检索。为了解决这一核心痛点,我们设计并实现了一套名为“学术云库”的在线文献浏览与管理系统。该系统采用经典的JSP与Servlet技术栈,旨在为高校实验室、研究团队及个人学者提供一个集中化、结构化、智能化的文献管理解决方案。
系统架构与技术栈
“学术云库”系统严格遵循模型-视图-控制器(MVC)设计模式,确保了代码的高内聚、低耦合,便于维护和扩展。整个技术架构清晰地将数据处理、业务逻辑和用户界面分离。
- 控制器层(Controller):基于Java Servlet实现。Servlet作为系统的中枢神经,负责拦截和处理所有来自客户端的HTTP请求。它解析请求参数,调用相应的业务逻辑组件(Service)进行处理,并根据处理结果决定将哪个视图(JSP页面)返回给用户。这种集中式的请求处理机制,使得业务逻辑的控制流清晰明了。
- 视图层(View):使用JSP(JavaServer Pages)技术结合JSTL(JSP Standard Tag Library)标签库和EL(Expression Language)表达式构建。JSP页面专注于数据的呈现,避免了在HTML中嵌入大量Java代码(Scriptlet),保持了页面的整洁。通过JSTL和EL,可以优雅地展示从Servlet传递过来的动态数据,实现了前后端的有效分离。
- 模型层(Model):由JavaBean实体类和数据访问对象(DAO)组成。实体类用于封装文献、用户等业务数据。DAO层使用JDBC(Java Database Connectivity)技术直接与MySQL数据库进行交互,负责执行所有数据的增、删、改、查(CRUD)操作。通过封装DAO模式,将数据持久化逻辑与业务逻辑解耦,提高了代码的可维护性和数据库的可移植性。
系统部署于Apache Tomcat等标准的Servlet容器中,整体架构稳健,为后续的功能迭代奠定了坚实的基础。
核心数据库设计剖析
数据库是系统的基石,其设计的优劣直接影响到系统的性能和数据一致性。“学术云库”采用MySQL数据库,其核心表结构设计体现了对文献管理业务的深刻理解。
1. 文献信息表(literature)
该表是系统的核心,用于存储所有文献的元数据信息。其设计亮点在于对文献属性的完整覆盖和关键字段的索引优化。
CREATE TABLE literature (
id int(11) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
author varchar(255) DEFAULT NULL,
keywords varchar(500) DEFAULT NULL,
abstract text,
file_path varchar(500) NOT NULL,
upload_time datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id),
KEY idx_title (title),
KEY idx_keywords (keywords(255)),
KEY idx_upload_time (upload_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 字段设计分析:
id:主键,采用自增整数,确保每条记录的唯一性,是数据关联的基础。title、author、keywords、abstract:这些字段完整地描述了文献的核心元数据。其中,keywords字段设置为varchar(500),为多关键词的存储提供了充足空间。abstract字段使用TEXT类型,以适应长篇摘要的存储需求。file_path:这是一个关键字段。它并不直接存储文献文件本身(如PDF),而是存储文件在服务器磁盘上的保存路径。这种设计避免了数据库因存储大文件而迅速膨胀,影响性能,符合最佳实践。文件上传功能将文件保存到指定目录,并将路径记录于此。upload_time:记录文献上传的时间,默认值为当前时间戳,便于按时间排序和筛选。
- 索引优化:为了支持高效的检索,表上建立了多个索引。
idx_title和idx_keywords索引极大地加速了按标题和关键词进行模糊搜索的查询速度。idx_upload_time索引则优化了按上传时间排序浏览的操作。
2. 用户信息表(user)
用户表负责管理系统用户的基本信息,支持系统的访问控制。
CREATE TABLE user (
id int(11) NOT NULL AUTO_INCREMENT,
username varchar(50) NOT NULL,
password varchar(50) NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY username (username)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 设计亮点:
username字段设置了UNIQUE唯一约束,保证了用户名的唯一性,这是用户身份标识的关键。- 在实际生产环境中,
password字段存储的应是经过哈希加密(如BCrypt)后的密文,而非明文,以保障用户密码安全。当前设计为简化演示,使用明文,但在正式系统中必须加强安全措施。
核心功能实现深度解析
结合代码片段与系统截图,我们将深入剖析“学术云库”的几个核心功能的实现机制。
1. 文献上传与元数据管理
用户可以将本地文献上传至系统,并同时填写相关的元数据信息。这是构建文献库的入口。
- 前端表单(JSP):表单使用
enctype="multipart/form-data"编码方式,以支持文件上传。<form action="LiteratureUploadServlet" method="post" enctype="multipart/form-data"> <label>文献标题:</label><input type="text" name="title" required> <label>作者:</label><input type="text" name="author"> <label>关键词:</label><input type="text" name="keywords"> <label>摘要:</label><textarea name="abstract"></textarea> <label>选择文件:</label><input type="file" name="file" accept=".pdf,.doc,.docx" required> <input type="submit" value="上传文献"> </form> - 后端处理(Servlet):
LiteratureUploadServlet负责处理上传请求。它使用Apache Commons FileUpload等库来解析 multipart 请求,将文件保存到服务器指定目录,并将元数据及文件路径存入数据库。@WebServlet("/LiteratureUploadServlet") public class LiteratureUploadServlet extends HttpServlet { protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { // 1. 检查请求是否为multipart if (!ServletFileUpload.isMultipartContent(request)) { // ... 错误处理 return; } // 2. 配置上传参数(如文件保存路径、最大文件大小等) DiskFileItemFactory factory = new DiskFileItemFactory(); ServletFileUpload upload = new ServletFileUpload(factory); try { // 3. 解析请求,获取表单项列表 List<FileItem> items = upload.parseRequest(request); String title = null; String author = null; // ... 其他字段 String fileName = null; for (FileItem item : items) { if (item.isFormField()) { // 处理普通表单字段 String fieldName = item.getFieldName(); String value = item.getString("UTF-8"); switch (fieldName) { case "title": title = value; break; case "author": author = value; break; // ... 其他字段 } } else { // 处理文件字段 fileName = new File(item.getName()).getName(); String filePath = getServletContext().getRealPath("/literature_files") + File.separator + fileName; File storeFile = new File(filePath); // 保存文件到磁盘 item.write(storeFile); } } // 4. 将元数据(title, author, fileName等)存入数据库 LiteratureDAO literatureDAO = new LiteratureDAO(); boolean success = literatureDAO.addLiterature(title, author, ..., fileName); // 5. 根据操作结果重定向或转发 if (success) { response.sendRedirect("upload_success.jsp"); } else { request.setAttribute("errorMessage", "文献上传失败!"); request.getRequestDispatcher("upload.jsp").forward(request, response); } } catch (Exception e) { throw new ServletException("文件上传失败", e); } } }
2. 文献检索与列表展示
系统提供强大的检索功能,用户可以通过标题、关键词等进行模糊搜索,结果以列表形式清晰展示。
- DAO层检索方法:
LiteratureDAO中的搜索方法使用SQL的LIKE语句实现模糊查询,并通过PreparedStatement防止SQL注入攻击。public class LiteratureDAO { public List<Literature> searchLiteratures(String keyword) { List<Literature> list = new ArrayList<>(); String sql = "SELECT * FROM literature WHERE title LIKE ? OR keywords LIKE ? ORDER BY upload_time DESC"; // 使用连接池或直接获取连接 try (Connection conn = getConnection(); PreparedStatement pstmt = conn.prepareStatement(sql)) { pstmt.setString(1, "%" + keyword + "%"); pstmt.setString(2, "%" + keyword + "%"); try (ResultSet rs = pstmt.executeQuery()) { while (rs.next()) { Literature lit = new Literature(); lit.setId(rs.getInt("id")); lit.setTitle(rs.getString("title")); lit.setAuthor(rs.getString("author")); // ... 设置其他属性 list.add(lit); } } } catch (SQLException e) { e.printStackTrace(); } return list; } } - 控制器与视图渲染:检索Servlet调用DAO方法获取数据列表,并将其存入request作用域,转发给JSP页面展示。
在JSP页面中,使用JSTL循环遍历列表。@WebServlet("/LiteratureSearchServlet") public class LiteratureSearchServlet extends HttpServlet { protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { String keyword = request.getParameter("keyword"); LiteratureDAO dao = new LiteratureDAO(); List<Literature> literatureList = dao.searchLiteratures(keyword); request.setAttribute("literatureList", literatureList); request.getRequestDispatcher("/literature_list.jsp").forward(request, response); } }<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %> <table> <tr><th>标题</th><th>作者</th><th>上传时间</th><th>操作</th></tr> <c:forEach var="literature" items="${literatureList}"> <tr> <td>${literature.title}</td> <td>${literature.author}</td> <td>${literature.uploadTime}</td> <td><a href="LiteratureDownloadServlet?id=${literature.id}">下载</a></td> </tr> </c:forEach> </table>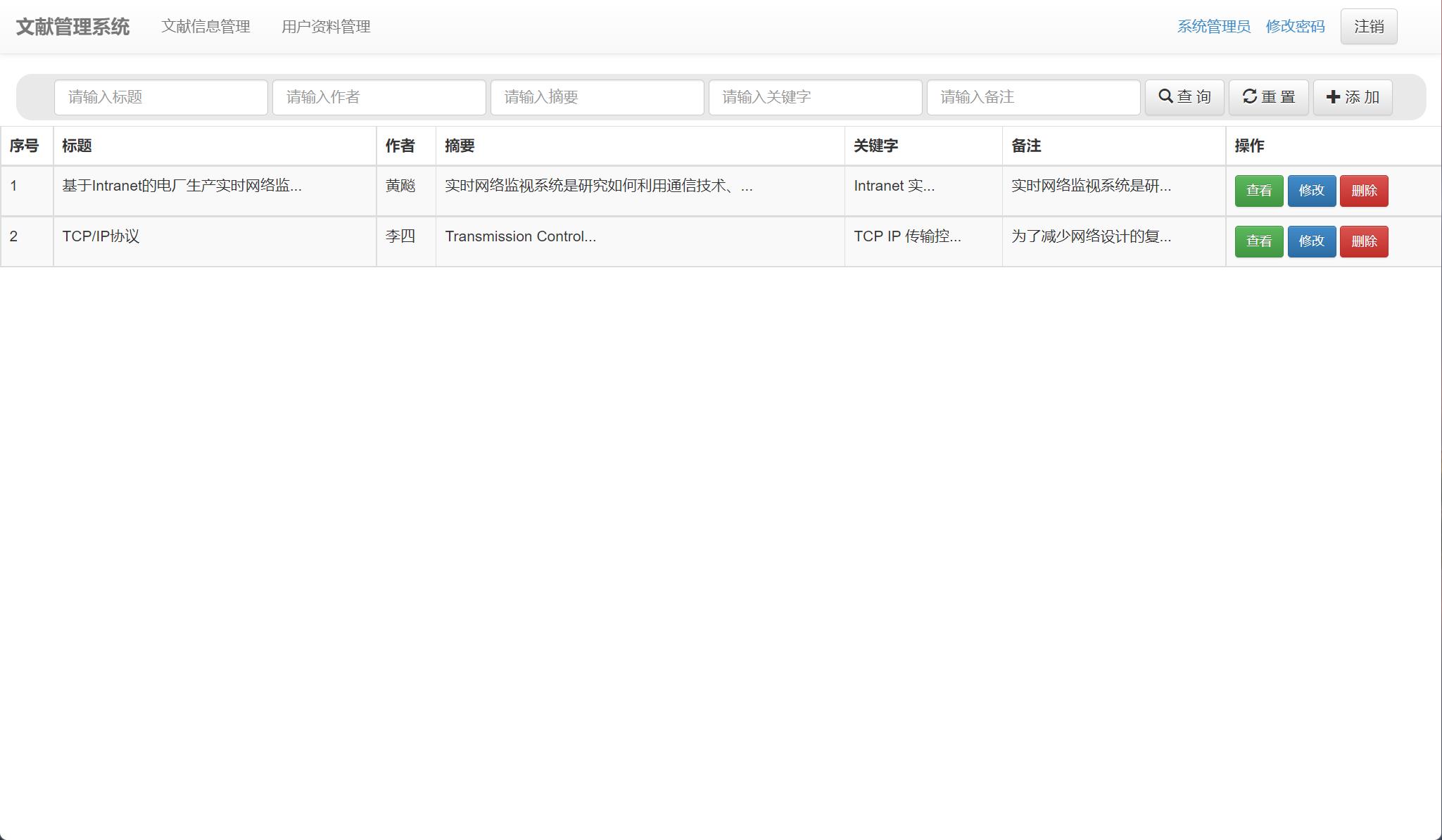
3. 文献文件下载
用户可以从列表中找到所需文献并直接下载到本地。
- 下载Servlet实现:该Servlet根据传入的文献ID,从数据库查询出文件路径,并设置正确的HTTP响应头,以附件形式将文件流式传输给浏览器。
@WebServlet("/LiteratureDownloadServlet") public class LiteratureDownloadServlet extends HttpServlet { protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { int literatureId = Integer.parseInt(request.getParameter("id")); LiteratureDAO dao = new LiteratureDAO(); Literature lit = dao.getLiteratureById(literatureId); // 根据ID获取文献对象,包含file_path if (lit != null) { String filePath = lit.getFilePath(); File downloadFile = new File(filePath); String mimeType = getServletContext().getMimeType(filePath); if (mimeType == null) { mimeType = "application/octet-stream"; // 默认二进制流 } response.setContentType(mimeType); response.setContentLength((int) downloadFile.length()); // 设置响应头,告知浏览器以下载方式处理 String headerKey = "Content-Disposition"; String headerValue = String.format("attachment; filename=\"%s\"", downloadFile.getName()); response.setHeader(headerKey, headerValue); // 使用Files.copy或IO流将文件内容写入response的输出流 Files.copy(downloadFile.toPath(), response.getOutputStream()); response.getOutputStream().flush(); } else { response.sendError(HttpServletResponse.SC_NOT_FOUND); } } }
实体模型与数据流转
系统的核心实体是Literature类,它是一个标准的JavaBean,用于在层之间传递数据。
public class Literature {
private Integer id;
private String title;
private String author;
private String keywords;
private String abstractText;
private String filePath;
private Timestamp uploadTime;
// 无参构造器、全参构造器、getter和setter方法
public Literature() {}
public Literature(Integer id, String title, String author, String keywords, String abstractText, String filePath, Timestamp uploadTime) {
this.id = id;
this.title = title;
this.author = author;
// ... 其他属性赋值
}
// ... 省略getter和setter
}
数据流转遵循典型MVC模式:用户请求 -> Servlet(控制器) -> 调用Service/DAO(模型) -> 返回数据 -> Servlet设置数据到请求域 -> 转发至JSP(视图) -> JSP渲染数据并生成HTML -> 返回给用户。
功能展望与优化方向
“学术云库”系统已具备文献管理的核心功能,但仍有广阔的优化和扩展空间。
- 全文检索能力:当前搜索基于元数据。未来可集成Apache Lucene或Elasticsearch等全文检索引擎,实现对PDF、Word文档内容的全文索引和搜索,极大提升检索深度和准确性。
- 在线阅读与标注:引入PDF.js等前端库,实现文献的在线预览。进一步开发在线标注、高亮、笔记功能,并将用户标注信息与文献关联存储,打造个人化的研究笔记系统。
- 高级用户权限与协作:扩展用户角色(如管理员、普通成员、访客),实现精细化的权限控制(如文献的增删改查权限)。支持创建“研究项目”或“团队空间”,实现文献在团队内的共享与协作管理。
- 文献推荐与智能分析:基于用户的浏览、下载历史和关键词,构建简单的推荐算法,主动推送相关文献。利用自然语言处理技术,自动提取文献的关键词和摘要,减轻用户上传时的负担。
- 数据可视化与统计:增加仪表盘功能,可视化展示文献库的增长趋势、热门研究领域、个人阅读统计等,为科研管理提供数据支持。
该系统通过严谨的MVC架构、优化的数据库设计以及清晰的代码实现,成功构建了一个稳定、高效的在线文献管理平台。其模块化的设计为应对未来复杂的需求变化和功能扩展提供了良好的技术基础,展现出传统JSP/Servlet技术在构建中小型Web应用中的强大生命力与实用性。